Method Overview
|
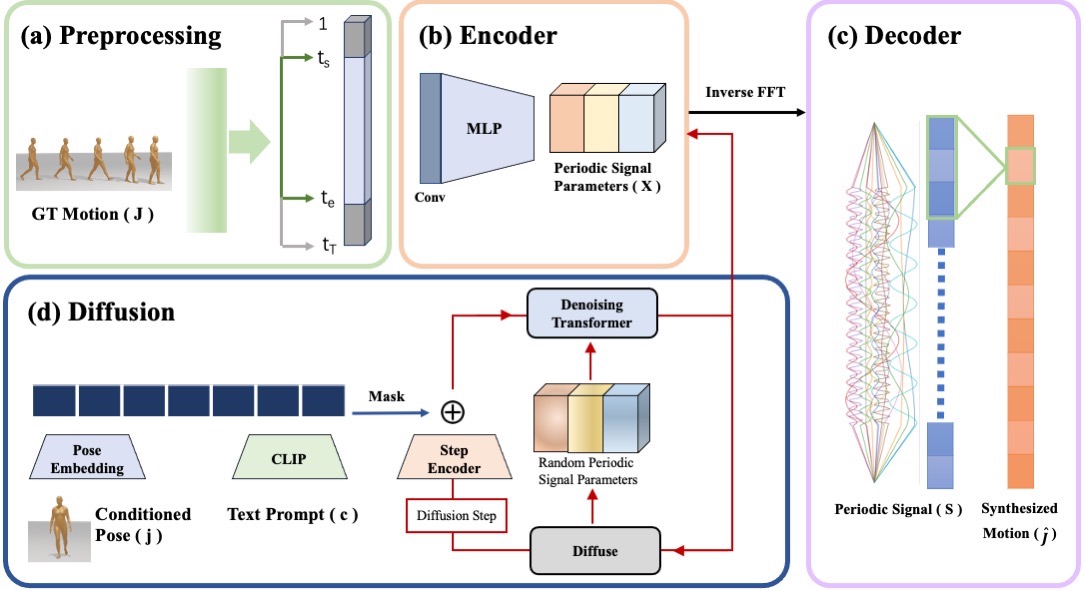
| Method Overview: (a) First, we conduct a preprocessing stage to isolate the periodic and non-periodic segments in the motion sequences. (b)-(c) Using the preprocessed movements, we then learn a network encoder to transform the motion space into a learned periodic parameterized phase space by minimizing the reconstruction errors between the original motions and the motions formed by decoding periodic parameters via Inverse FFT. (d) Next, we train a conditional diffusion model to predict the periodic parameters with a text prompt and a starting pose as inputs. During inference time, given a text prompt and a starting pose, we apply diffusion to predict the periodic parameters and then decode the motion from the signal. |